2.1 오라클 HA 아키텍처에서 발생하는 다양한 유형의 다운타임 및 대응 솔루션
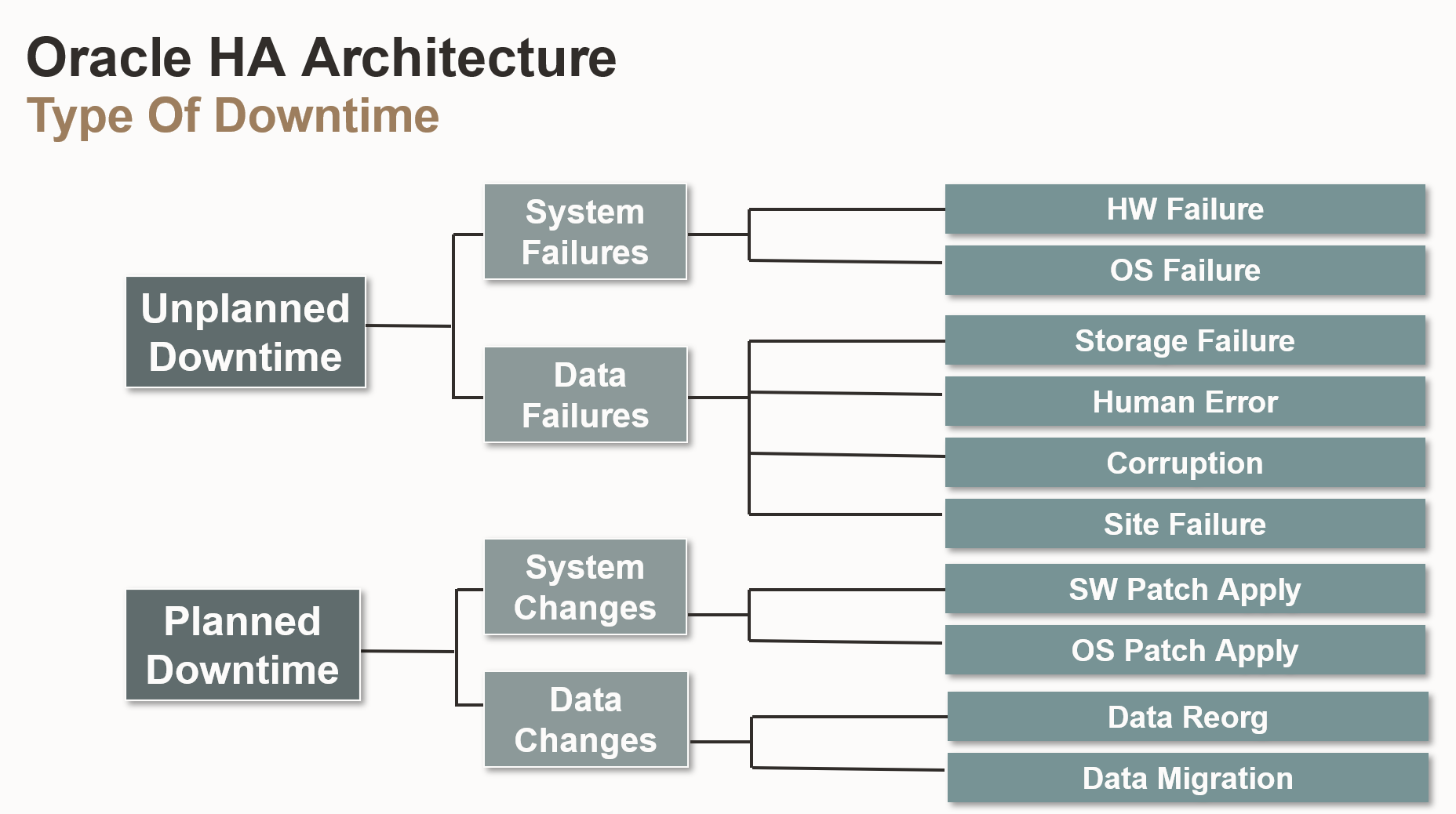
- Unplanned Downtime (계획되지 않은 다운타임)
- System Failures (시스템 실패)
- HW Failure (하드웨어 실패 ): 서버, 디스크, 네트워크 장비 등의 하드웨어 고장으로 인해 발생하는 다운타임
- OS Failure (운영 체제 실패): 운영 체제의 오류, 충돌, 또는 예상치 못한 종료로 인해 발생하는 다운타임
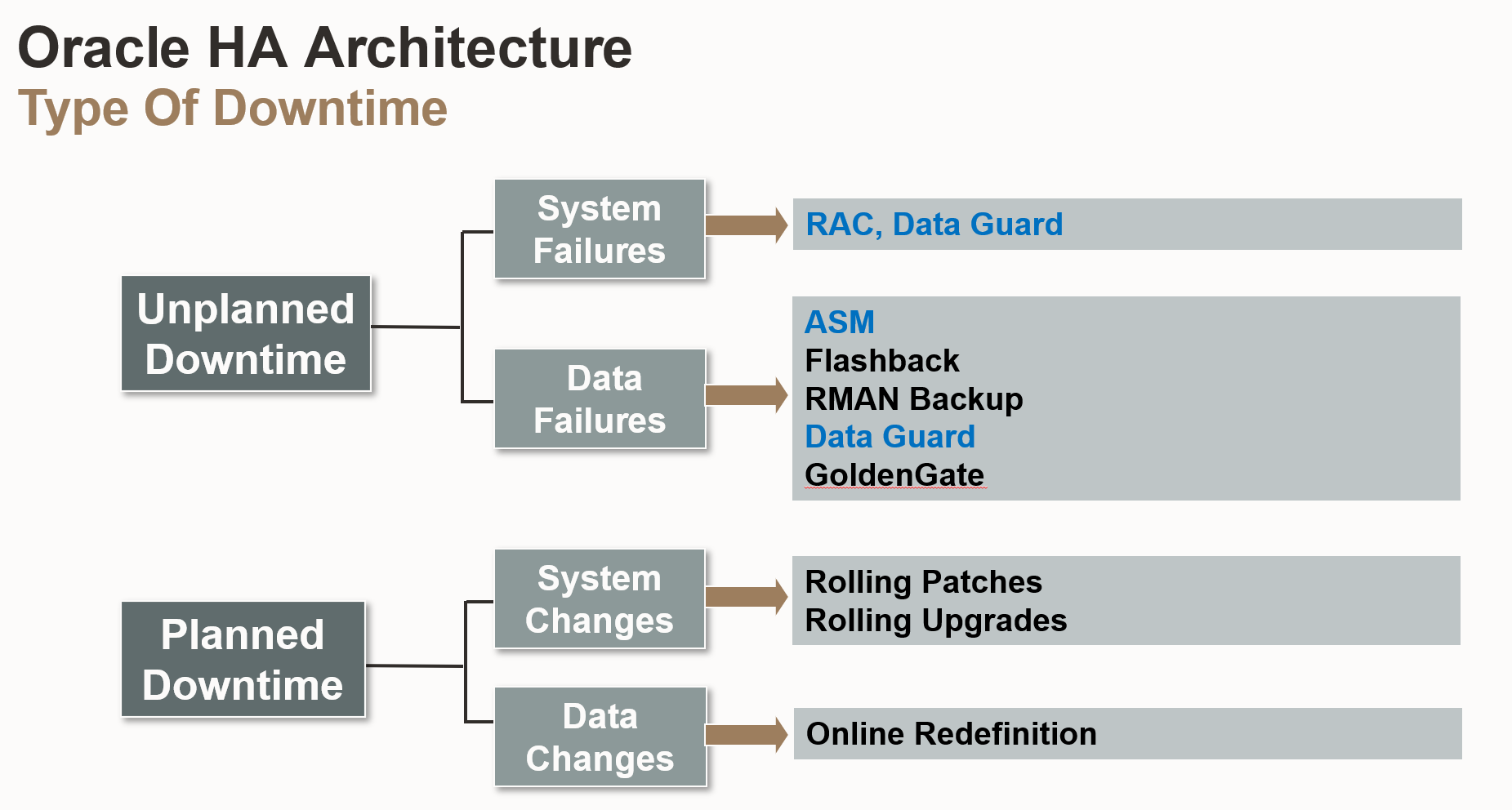
- 대응 솔루션: RAC(Real Application Clusters) 및 Data Guard를 사용하여 시스템 실패 시에도 다른 노드로 서비스를 즉시 전환하여 다운타임을 최소화
- Data Failures (데이터 실패)
- Storage Failure (저장소 실패): 데이터 저장 장치(디스크, 스토리지 시스템)의 고장으로 인해 발생하는 다운타임
- Human Error (인적 오류): 데이터베이스 관리자나 사용자의 실수로 인해 발생하는 다운타임
- Corruption (데이터 손상): 데이터 파일이나 데이터베이스 객체가 손상되어 발생하는 다운타임
- Site Failure (사이트 실패): 데이터 센터나 전체 시스템이 물리적인 재해(화재, 지진 등)로 인해 발생하는 다운타임
- 대응 솔루션: ASM(Automatic Storage Management)을 사용하여 저장소 오류를 방지하고, Flashback, RMAN Backup, Data Guard, GoldenGate를 사용하여 데이터 복구 용이성 확보 및 손실 최소화
- System Failures (시스템 실패)
- Planned Downtime (계획된 다운타임)
- System Changes (시스템 변경)
- SW Patch Apply (소프트웨어 패치 적용): 데이터베이스 소프트웨어나 관련 소프트웨어에 패치를 적용하기 위해 발생하는 다운타임
- OS Patch Apply (운영 체제 패치 적용) 운영 체제에 패치를 적용하기 위해 발생하는 다운타임
- 대응 솔루션: Rolling Patches 및 Rolling Upgrades를 사용하여 시스템 변경 시에도 서비스를 중단하지 않고 연속적으로 운영가능
- Data Changes (데이터 변경)
- Data Reorg (데이터 재구성): 데이터베이스 객체의 구조를 변경하거나 데이터를 재구성하기 위해 발생하는 다운타임
- Data Migration (데이터 마이그레이션): 데이터를 다른 시스템이나 데이터베이스로 이전하기 위해 발생하는 다운타임
- 대응 솔루션: Online Redefinition을 사용하여 데이터 변경 시에도 서비스를 중단하지 않고 온라인 상태에서 작업 수행가능
- System Changes (시스템 변경)
2.2 RAC (Real Application Clusters)
2.2.1 HA (Active & Stanby) vs RAC
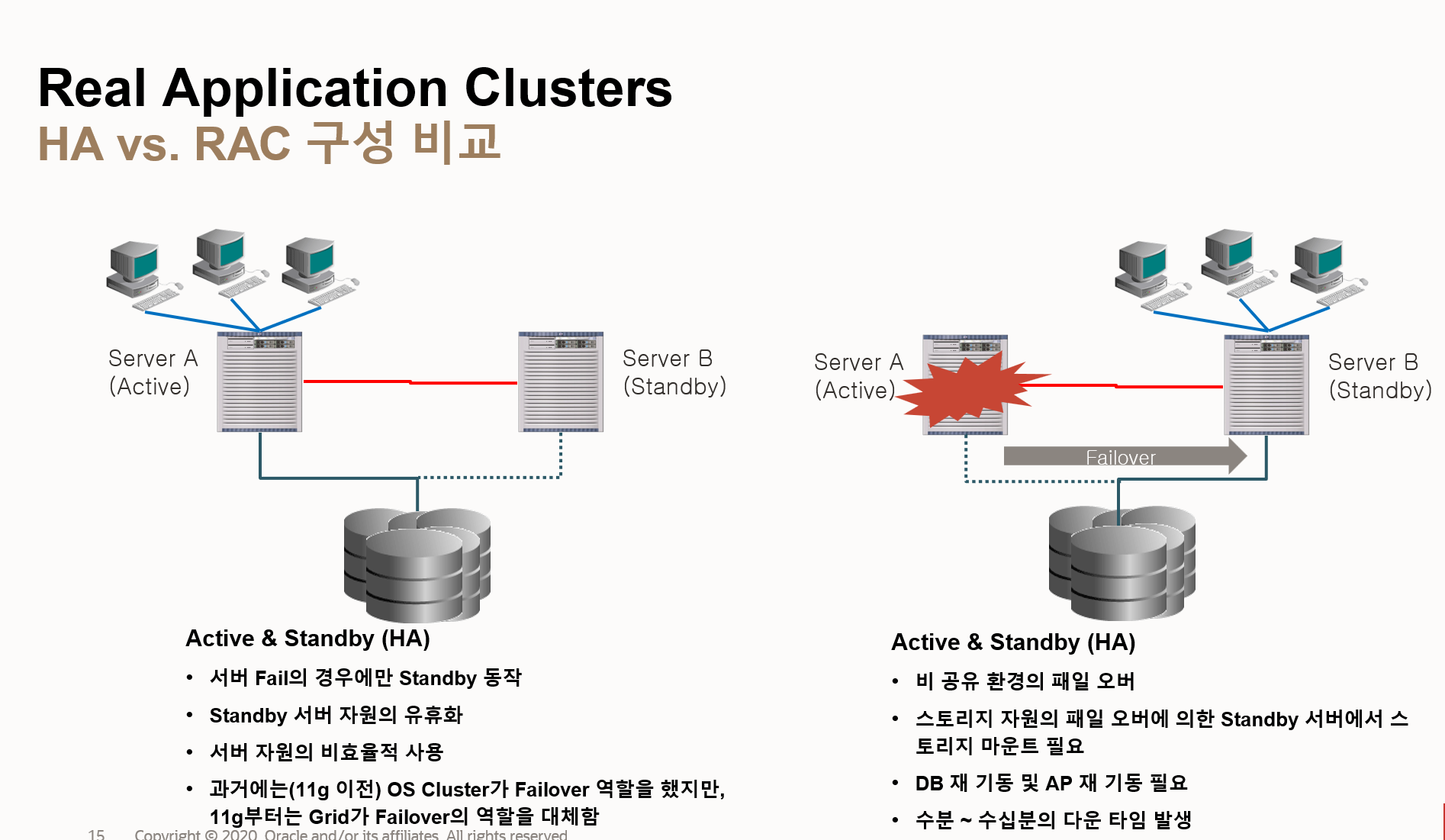
- Active & Standby (HA 구성)
- 단일 활성 서버: 하나의 서버(Server A)만 활성화되어 서비스를 제공하고, 다른 서버(Server B)는 대기(Standby) 상태로 유지
- 서버 실패 시 대기 서버 활성화: 활성 서버에 장애가 발생하면 대기 서버가 활성화되어 서비스를 이어받음
- 대기 서버 자원 유휴화: 대기 서버는 평상시에는 유휴 상태로 유지되어 자원 활용도 낮음
- OS 클러스터 기반 페일오버 (과거): 과거에는 OS 클러스터가 페일오버 역할을 수행했지만, 오라클 11g부터는 Grid Infrastructure가 페일오버 역할 대체
- 비공유 환경: 스토리지 자원이 공유되지 않으므로, 페일오버 시 대기 서버에서 스토리지 마운트 필요
- DB 및 AP 재기동 필요: 페일오버 후 데이터베이스와 애플리케이션 재기동 필요
- 수분~수십 분 다운타임 발생: 페일오버 과정에서 수분에서 수십 분의 다운타임 발생
- Active & Active (RAC 구성)
- 다중 활성 서버: 여러 서버(Server A, Server B 등)가 동시에 활성화되어 서비스 제공
- 로드 밸런싱: 여러 서버가 작업을 분산 처리하여 성능을 향상할 수 있음
- 서버 실패 시 서비스 연속성 유지: 일부 서버에 장애가 발생해도 다른 서버들이 서비스를 계속 제공하여 다운타임 최소화
- 공유 스토리지 사용: 모든 서버가 공유 스토리지를 사용하여 데이터 일관성 유지
- Cache Fusion: 서버 간 데이터 블록 공유 및 동기화를 통해 성능 향상
- Transparent Application Failover (TAF): 애플리케이션 연결이 자동으로 다른 서버로 전환되어 사용자에게 투명한 페일오버 제공
| 특징 | HA 구성 | RAC 구성 |
| 활성 서버 수 | 1개 | 여러 개 |
| 자원 활용 도 | 낮음 | 높음 |
| 페일오버 속도 | 느림 (수분~ 수십 분) | 빠름 (TAF 사용 시 투명) |
| 스토리지 | 비공유 | 공유 |
| 복잡성 | 낮음 | 높음 |
| 비용 | 낮음 | 높음 |
2.2.2 오라클 RAC 환경의 작동 방식과 장점
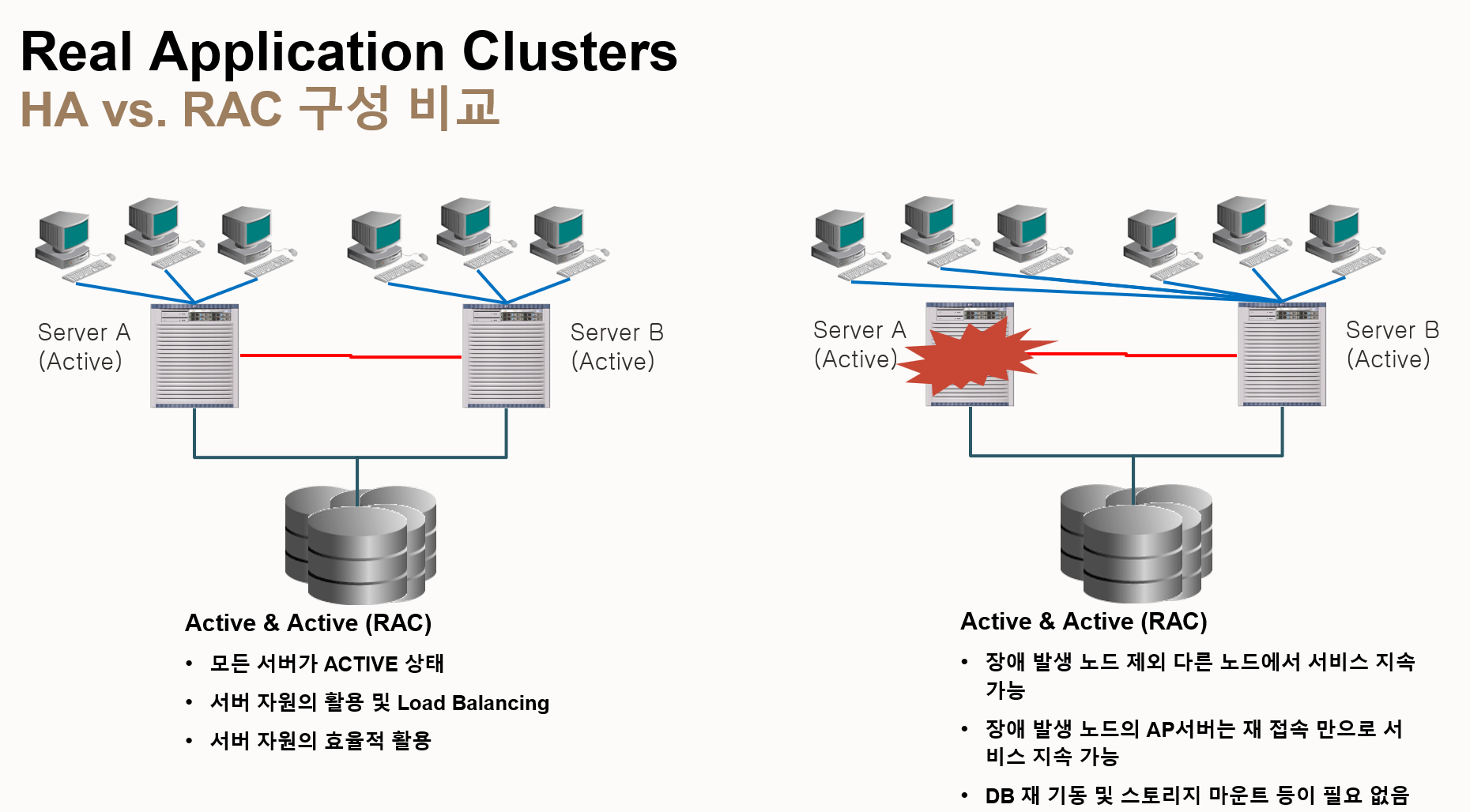
- 왼쪽 그림 (정상 작동 시)
- Active & Active 상태: 모든 서버(Server A, Server B)가 활성화되어 서비스 제공
- 로드 밸런싱: 여러 서버가 작업을 분산 처리하여 성능 향상
- 자원 효율적 활용: 모든 서버가 활성화되어 자원을 효율적으로 활용
- 오른쪽 그림 (장애 발생 시)
- 장애 발생 노드 제외 서비스 지속: Server A에 장애가 발생하더라도 Server B가 서비스를 계속 제공하여 다운타임 최소화
- AP 서버 재접속: 장애 발생 노드에 연결된 애플리케이션 서버(AP 서버)는 재접속만으로 서비스 지속
- DB 재기동 및 스토리지 마운트 불필요: RAC는 공유 스토리지를 사용하므로, 장애 발생 시 데이터베이스를 재기동하거나 스토리지를 마운트 할 필요 없음
- RAC (Real Application Clusters) 환경에서 데이터 버퍼 캐시 (Data Buffer Cache)는 각 인스턴스 간에 데이터를 전달해야 하므로 인터커넥트 (interconnect) 속도가 매우 중요
- 인터커넥트의 역할
- 데이터 블록 전달: RAC 환경에서 각 인스턴스는 자체적인 데이터 버퍼 캐시를 가지고 있으며, 한 인스턴스에서 데이터 블록을 요청했는데 해당 블록이 다른 인스턴스의 버퍼 캐시에 있는 경우, 인터커넥트를 통해 해당 블록을 전달받음
- Cache Fusion (캐시 퓨전): 인스턴스 간 데이터 블록 전달을 효율적으로 처리하는 기술
- Global Cache Service (글로벌 캐시 서비스): 데이터 블록의 일관성을 유지하고 인스턴스 간 동기화를 관리
- 인터커넥트 속도의 중요성
- 성능 영향: 인터커넥트 속도가 느리면 데이터 블록 전달 시간이 길어져 전체 시스템 성능 저하 발생
- 전용 스위치 구성 필요: 높은 성능을 위해 인터커넥트 전용 스위치를 구성을 권장
- 네트워크 구성: 고속 네트워크 인터페이스 (예: 10 GbE 이상)와 저지연 네트워크 프로토콜 (예: InfiniBand) 사용 권장
- 인터커넥트의 역할
2.2.3 오라클 RAC 아키텍처
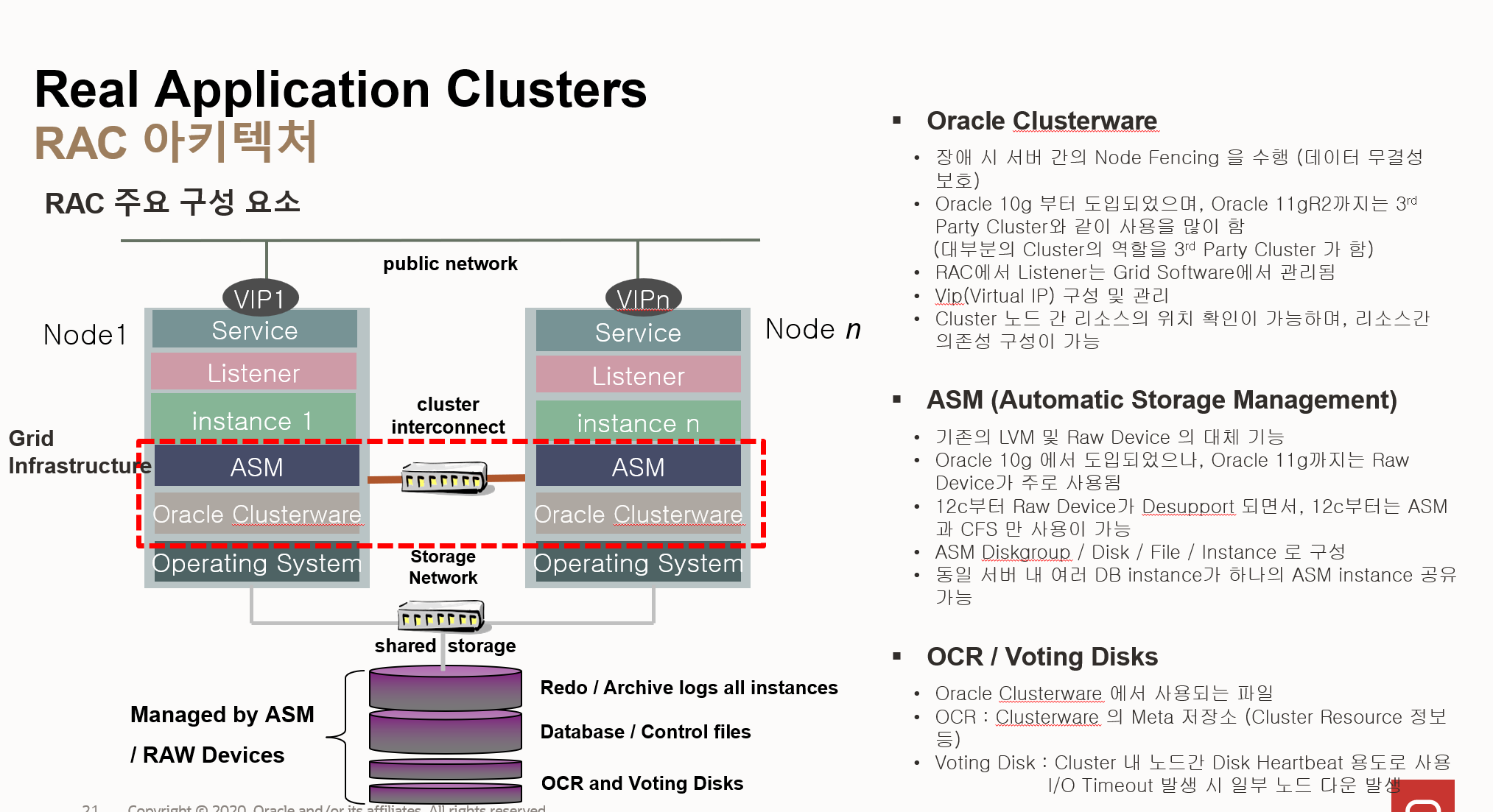
- RAC 아키텍처 주요 구성 요소
- Grid Infrastructure:
- RAC 환경의 핵심 기반 소프트웨어
- Oracle Clusterware와 ASM (Automatic Storage Management)으로 구성
- 클러스터 관리, 스토리지 관리, 네트워크 관리 기능 제공
- Oracle Clusterware:
- 클러스터 노드 간의 통신 및 관리 담당
- 노드 추가/삭제, 장애 감지, 리소스 관리 등의 기능 수행
- 장애 발생 시 서버 간의 Node Fencing을 수행하여 데이터 무결성 보호
- Oracle 10g부터 도입되었으며, Oracle 11gR2까지는 3rd Party Cluster와 함께 사용되었음
- 12c부터는 Grid Software에서 관리하는 HAC (High Availability Cluster) Listener의 역할 수행
- VIP (Virtual IP) 구성 및 관리 담당
- 클러스터 노드 간 리소스의 위치 확인 및 리소스 간 의존성 구성 기능 제공
- ASM (Automatic Storage Management):
- 기존 LVM (Logical Volume Manager) 및 Raw Device를 대체하는 스토리지 관리 기능
- Oracle 10g에서 도입되었으나, Oracle 11g까지는 주로 Raw Device가 사용
- 12c부터 Raw Device가 지원 중단되면서 ASM과 CFS (Cluster File System)만 사용 가능
- ASM Diskgroup/Disk/File/Instance 등의 스토리지 객체 관리
- 동일 서버 내 여러 DB instance가 하나의 ASM instance를 공유할 수 있음
- 공유 스토리지 (Shared Storage):
- 모든 RAC 노드가 공유하는 스토리지 영역
- 데이터 파일, 컨트롤 파일, 리두 로그 파일 등을 저장
- ASM에 의해 관리됨
- OCR (Oracle Cluster Registry) / Voting Disks:
- Oracle Clusterware에서 사용하는 파일
- OCR: Clusterware의 메타 저장소로, 클러스터 리소스 정보 등을 저장
- Voting Disks: 클러스터 노드 간의 디스크 Heartbeat 용도로 사용되며, I/O timeout 발생 시 일부 노드가 다운될 수 있음
- 클러스터 인터커넥트 (Cluster Interconnect):
- 클러스터 노드 간의 통신을 위한 네트워크
- 고속 네트워크 (예: InfiniBand)를 사용하여 데이터 블록 전송 성능을 높임
- 공용 네트워크 (Public Network):
- 클라이언트가 데이터베이스에 접속하는 데 사용하는 네트워크
- VIP (Virtual IP)를 통해 접속
- Grid Infrastructure:
2.2.4 오라클 RAC Clusterware
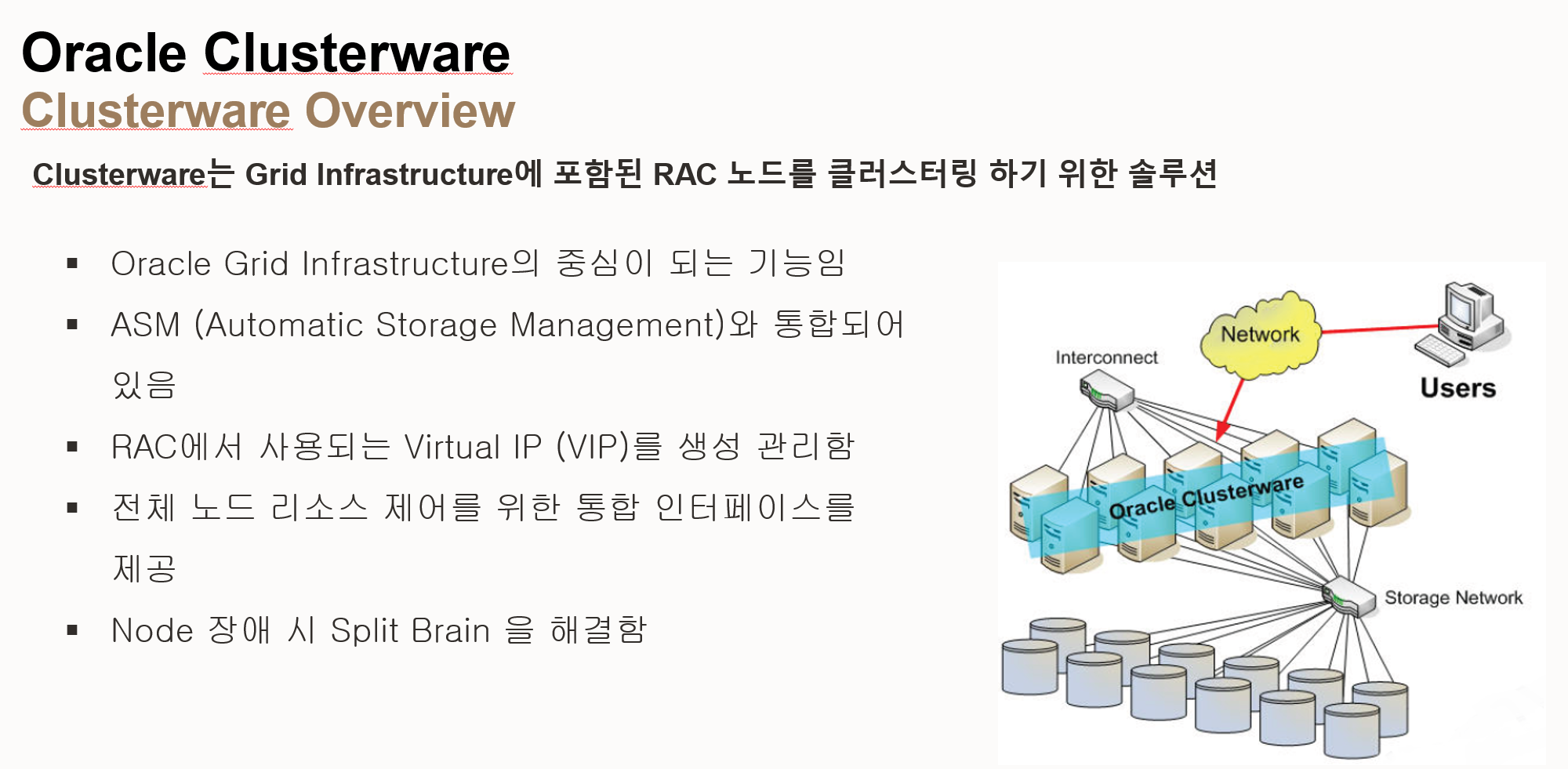
- Oracle Clusterware Overview (오라클 클러스터웨어 개요)
- Grid Infrastructure의 구성 요소: 클러스터웨어는 Grid Infrastructure에 포함된 RAC 노드를 클러스터링 하기 위한 솔루션
- Grid Infrastructure의 중심 기능: 오라클 Grid Infrastructure의 중심이 되는 기능
- ASM과 통합: ASM (Automatic Storage Management)과 통합되어 있음
- VIP 생성 및 관리: RAC에서 사용되는 VIP (Virtual IP)를 생성 및 관리
- 통합 인터페이스 제공: 전체 노드 리소스 제어를 위한 통합 인터페이스 제공
- Split Brain 해결: 노드 장애 시 Split Brain 문제 해결
- 이미지 구성 요소
- Network: 클라이언트가 데이터베이스에 접속하는 데 사용하는 네트워크
- Interconnect: 클러스터 노드 간의 통신을 위한 네트워크
- Users: 데이터베이스를 사용하는 클라이언트
- Oracle Clusterware: 클러스터 노드 간의 통신 및 관리를 담당하는 소프트웨어
- Storage Network: 공유 스토리지를 연결하는 네트워크

- 리소스 종류:
- VIP (Virtual IP): 클러스터 환경에서 클라이언트 접속을 위한 가상 IP 주소
- Listener: 클라이언트 연결 요청을 수신하고 데이터베이스로 연결을 중재하는 프로세스
- Public Network Monitoring: 공용 네트워크의 상태를 모니터링
- SCAN (Single Client Access Name) Listener: 클라이언트가 RAC 데이터베이스에 접속할 때 사용하는 단일 접속 이름
- SCAN VIP: SCAN Listener가 사용하는 가상 IP 주소
- ASM (Automatic Storage Management): 오라클 데이터베이스 전용의 스토리지 관리 시스템
- ASM Data Group: ASM 디스크 그룹을 관리
- Database: 데이터베이스 인스턴스를 관리
- Instance: 데이터베이스 인스턴스를 관리
- 리소스 상태 확인 명령어: crsctl stat res -t 명령어를 사용하여 리소스의 상태를 확인가능
- 리소스 상태 정보:
- Name: 리소스 이름
- Target State: 목표 상태 (ONLINE, OFFLINE)
- Server: 리소스가 실행 중인 서버
- State details: 리소스의 상세 상태 (STABLE 등)

- 스플릿 브레인 (Split Brain) 개념
- 정의: 클러스터 노드 간의 Heartbeat 네트워크가 단절된 상태에서 노드들이 여전히 작동하는 상황
- 문제점: 각 노드가 독립적으로 작동하면서 데이터 불일치(Data Corruption)가 발생할 수 있음
- 해결 방법: 데이터 정합성을 위해 클러스터 내 일부 노드를 제거(Eviction)해야 함
- IO Fencing (IO 펜싱)
- 정의: 스플릿 브레인 상황에서 제거(Evicted)된 노드가 공유 디스크에 접근하지 못하도록 IO를 차단
- 목적: 데이터 손상 방지
- IO Fencing 방법
- STONITH (Shoot The Other Node In The Head): 정상적인 노드가 문제가 있는 노드를 강제로 Shutdown 하는 방식
- Self-fencing: /etc/init.d/init.cssd를 스스로 수행하여 리부트 하는 방식
2.2.5 오라클 RAC TAF (Transparent Application Failover) / CTF (Connection Time Failover)

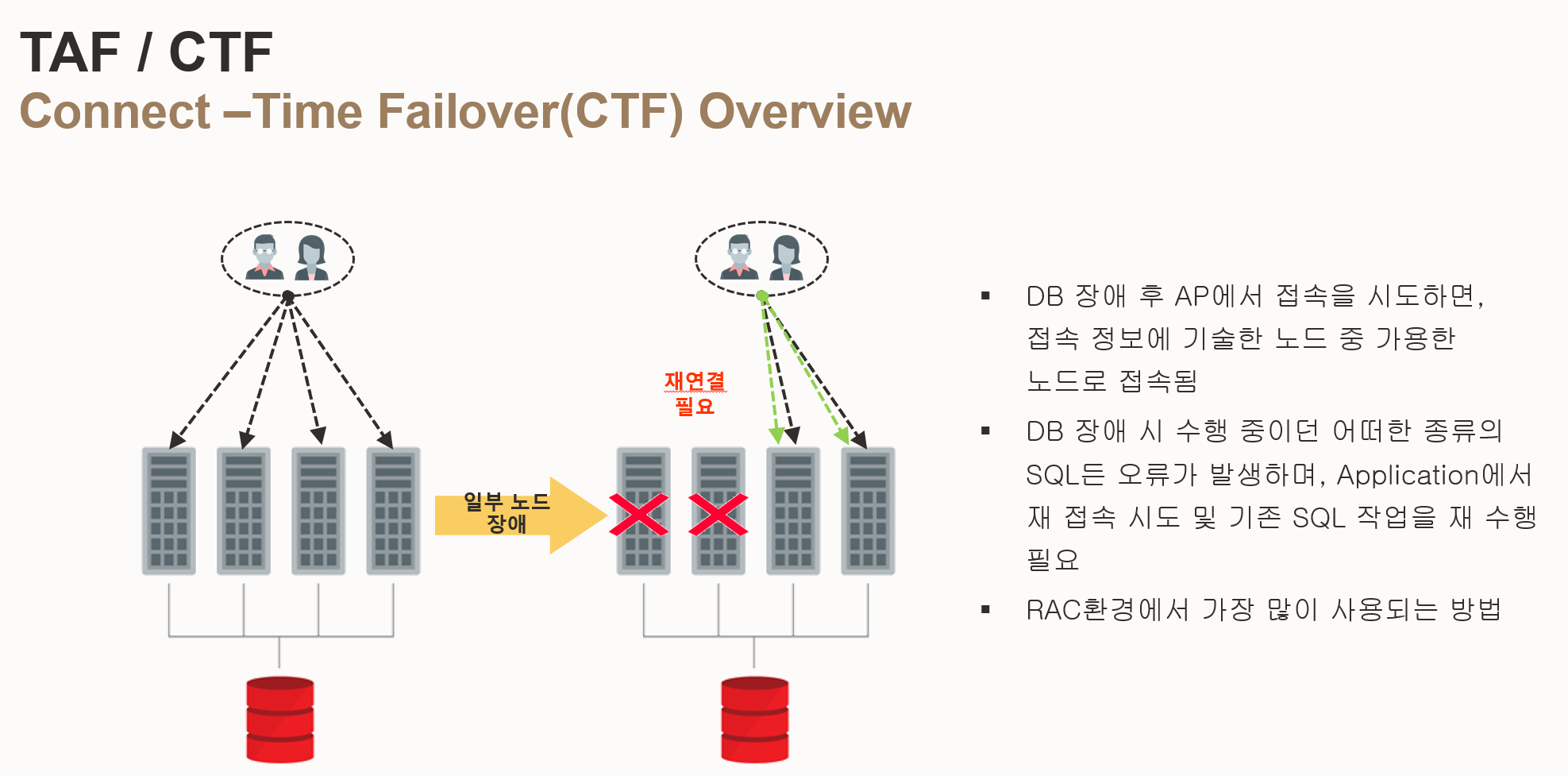
- CTF (Connection Time Failover) 개요
- 사용자 재연결 필요: RAC 환경에서 일부 인스턴스가 다운되었을 때, 사용자가 직접 연결을 재시도해야 함
- TNS 설정 기반: TNS(Transparent Network Substrate)에 기술된 IP 주소 중 접속 가능한 인스턴스로 연결됨
- 단순 연결 전환: 단순히 연결을 다른 인스턴스로 전환하는 기능만 제공
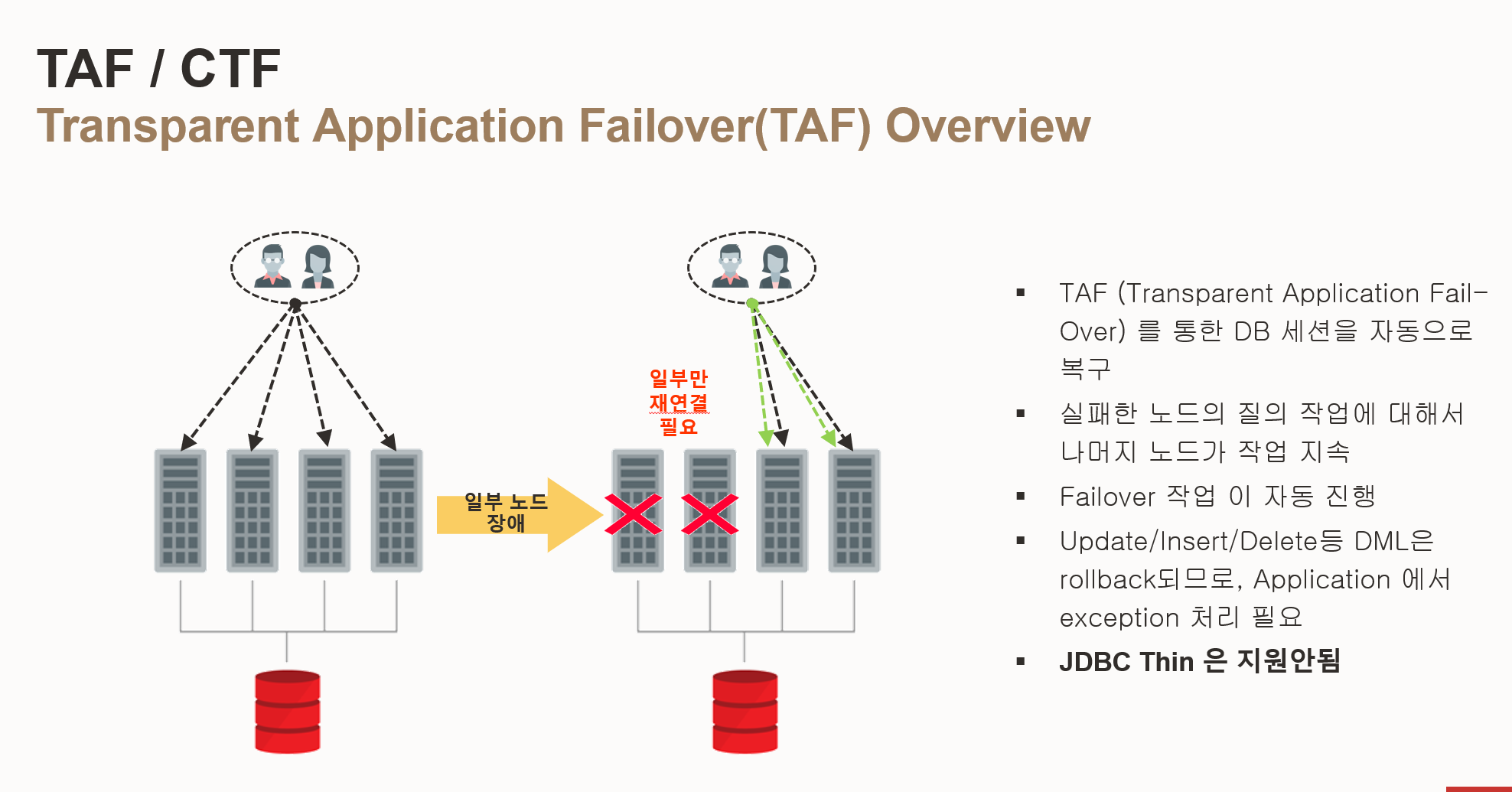
- TAF (Transparent Application Failover) 개요
- 자동 세션 복구: 세션이 끊기더라도 SQL*Net이 자동으로 살아있는 노드로 세션을 재연결됨 (일부 세션 제외)
- 데이터 변경 없는 세션 복구: 조회(SELECT) 또는 유휴(IDLE) 상태의 세션은 자동으로 복구
- 데이터 변경 트랜잭션 롤백: 데이터 변경이 있는 트랜잭션은 재접속이 필요하며, 변경된 데이터는 자동으로 롤백
- 애플리케이션 투명성: 애플리케이션은 장애 발생을 인지하지 못하고 계속 작동할 수 있음
- 작업 지속: 실패한 노드의 질의 작업에 대해서 나머지 노드가 작업 지속
- 자동 페일오버: 페일오버 작업이 자동으로 진행
- DML 롤백 및 예외 처리: Update/Insert/Delete 등 DML은 롤백되므로 애플리케이션에서 예외 처리 필요
- JDBC Thin 미지원: JDBC Thin 드라이버는 TAF를 지원하지 않음
| 기능 | CTF | TAF |
| 세션 복구 방식 | 사용자 재연결 | 자동 세션 복구 |
| 지원 범위 | 모든 세션 | 데이터 변경 없는 세션 자동 복구 |
| 애플리케이션 영향 | 재연결 코드 필요 | 투명한 장애 처리 |
| 트랜잭션 처리 | 재연결 후 수동 처리 | 자동 롤백 및 재연결 후 수동 처리 |
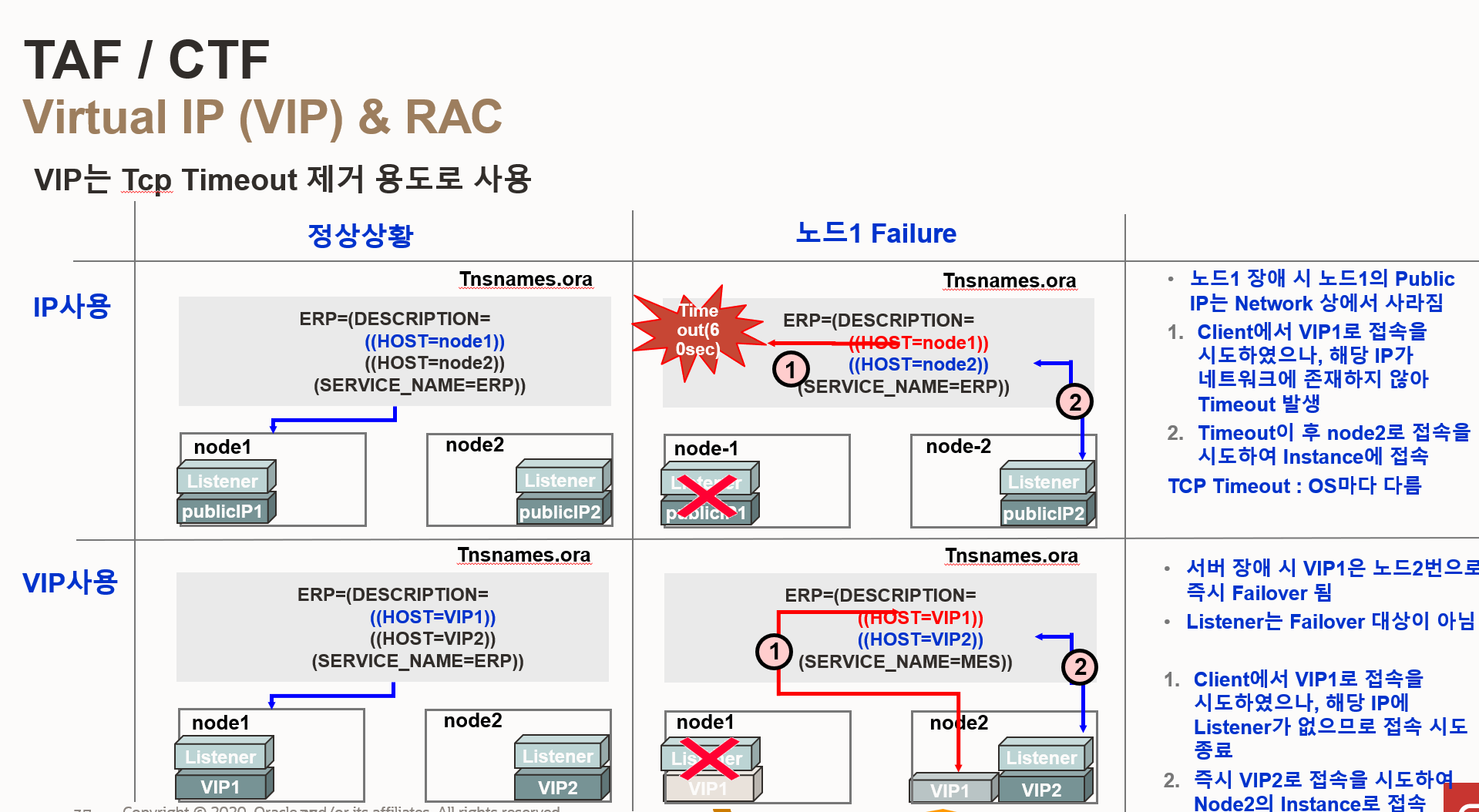
- RAC 환경에서 TNSNAMES.ORA 파일 설정 시, PUBLIC IP 대신 VIRTUAL IP(VIP)를 사용하면 장애 발생 시 클러스터가 더 빠르게 감지하고 페일오버를 수행하여 서비스 연속성을 높일 수 있음
- 클러스터웨어는 VIP의 상태를 지속적으로 모니터링
- VIP는 클라이언트에게 고정된 접속 주소를 제공
- 노드 장애 시에도 클라이언트는 VIP를 통해 계속해서 데이터베이스에 접속할 수 있음
- PUBLIC IP를 사용하는 경우, 클라이언트는 장애 발생 노드의 IP 주소 변경필요
- SCAN VIP를 사용하면 클라이언트 연결 요청을 클러스터 내의 활성 노드에 분산이 가능하며 RAC 데이터베이스의 성능과 가용성을 향상
2.3 오라클 Data Guard (Active Data Guard)
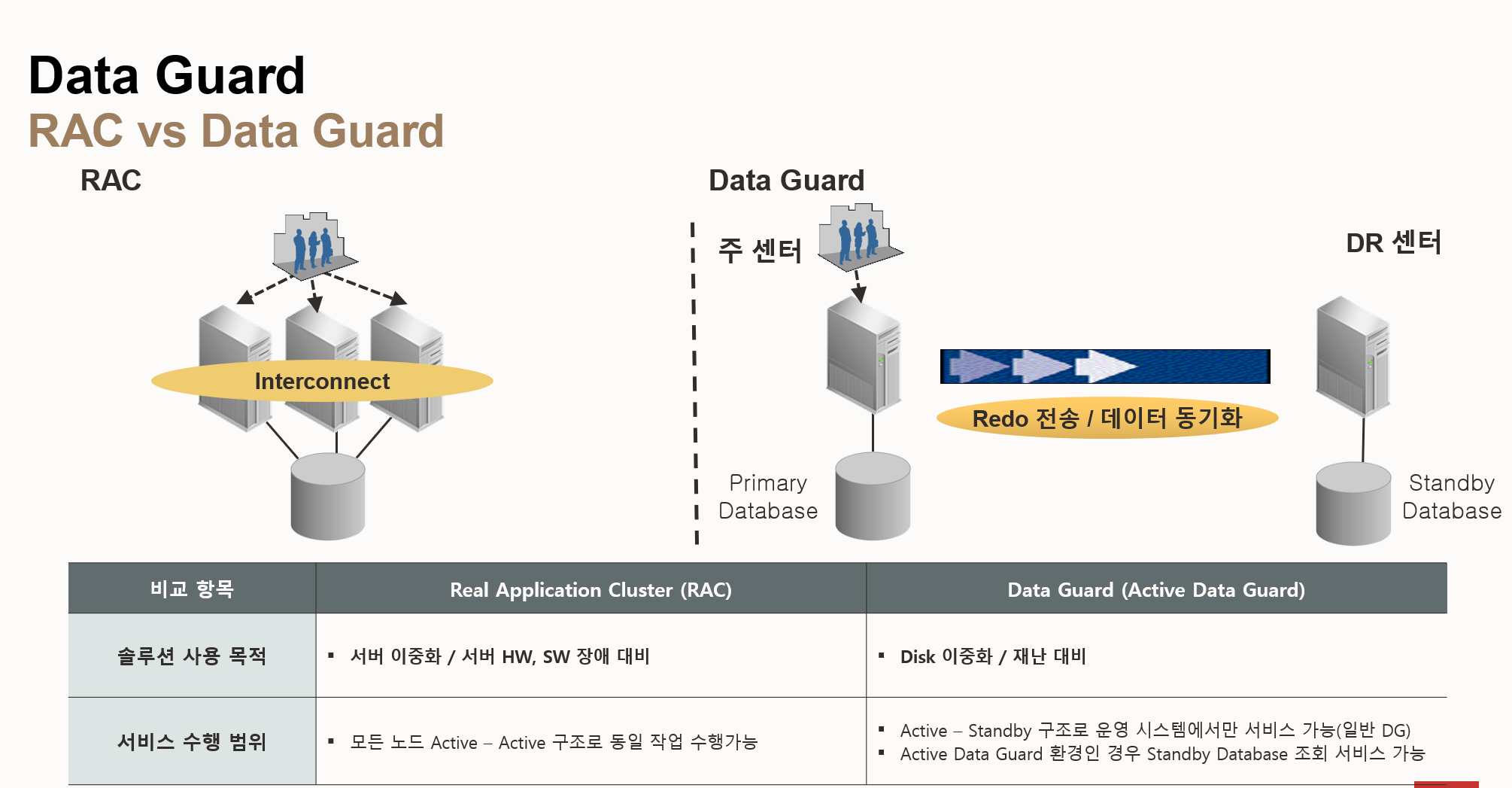
- RAC (Real Application Clusters)
- 목적: 서버 이중화 및 서버 HW/SW 장애 대비
- 구조: 모든 노드가 Active-Active 구조로 동일한 작업 수행
- 작동 방식: Interconnect를 통해 노드 간 데이터를 공유하고 동기화
- Data Guard
- 목적: 디스크 이중화 및 재난 대비
- 구조: Active-Standby 구조로 운영 시스템에서만 서비스 제공 (일반 Data Guard)
- Active Data Guard: Standby 데이터베이스에서 조회 서비스를 제공
- 작동 방식: Redo 로그 파일을 DR 센터의 Standby 데이터베이스로 전송하여 데이터 동기화
- Data Guard Broker: Data Guard 생성, 관리, 모니터링을 중앙에서 관리 가능
- Switchover: 개발 또는 테스트 목적으로 주 센터와 DR 센터의 역할 전환
- Failover: 주 센터에 장애가 발생했을 때 DR 센터를 주 센터로 전환 (주 센터는 더 이상 사용 불가)
| 비교항목 | RAC (Real Application Clusters) | Data Guard (Active Data Guard) |
| 솔루션 사용 목적 | 서버 이중화 / 서버 HW, SW 장애 대비 | 디스크 이중화 / 재난 대비 |
| 서비스 수행범위 | 모든 노드 Active - Active 구조로 동일 작업 수행 가능 | Active-Standby 구조로 운영 시스템에서만 서비스 가능 (일반 DG) <br> Active Data Guard 환경인 경우 Standby Database 조회 서비스 가능 |
| 데이터 동기화 방식 | Interconnect를 통한 데이터 블록 공유 | Redo 로그 파일 전송 |
| 장애 복구 방식 | 노드 간 Failover | DR 센터로 Failover |
| 데이터 손실 가능성 | 거의 없음 | 장애 발생 시 일부 데이터 손실 가능성 존재 |
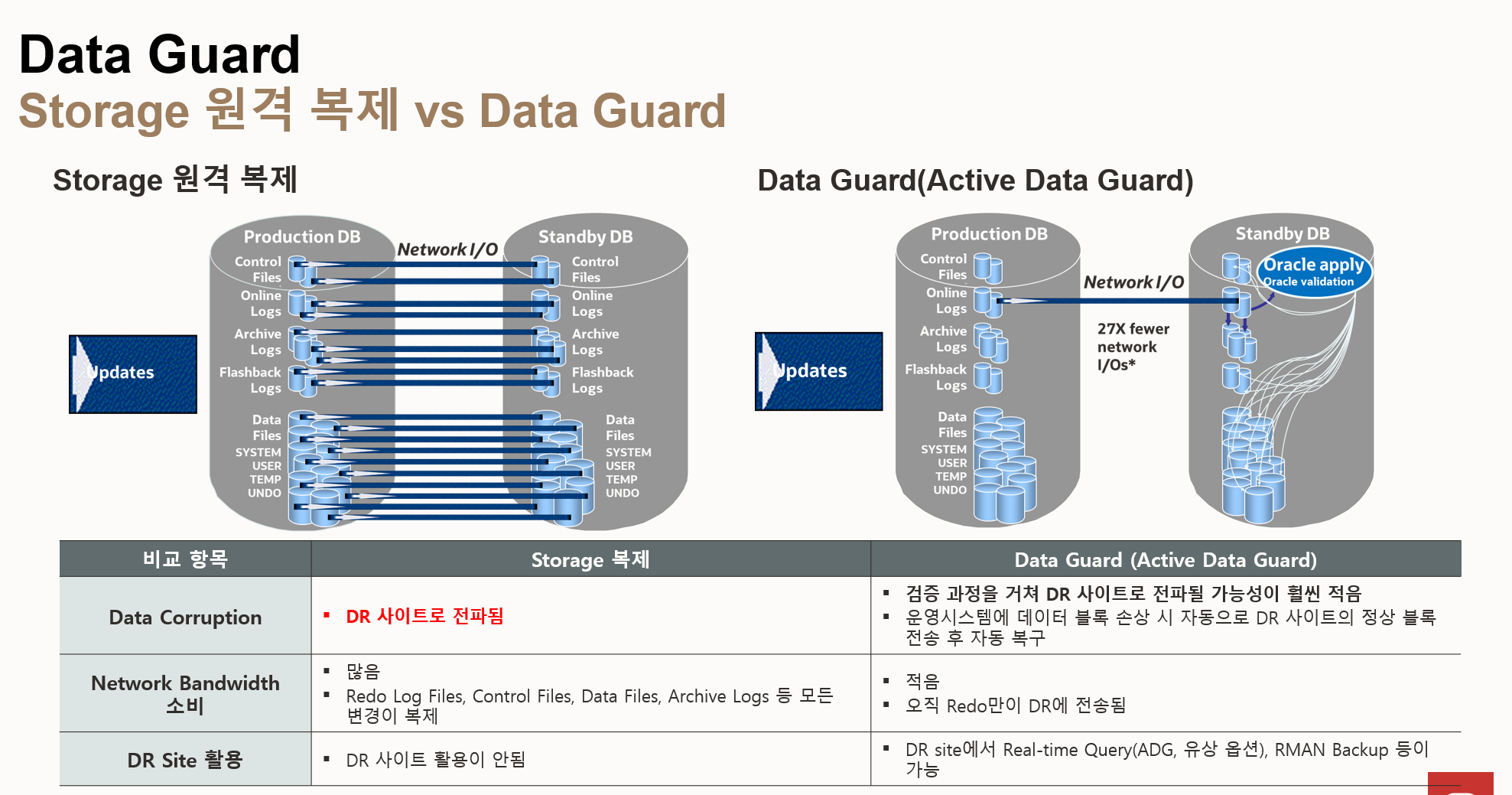
- 스토리지 원격 복제
- 복제 방식: 운영 DB의 모든 데이터 파일, 컨트롤 파일, 리두 로그 파일 등을 DR 사이트로 복제
- 데이터 손상 전파: 운영 DB에서 데이터 손상이 발생하면 DR 사이트로도 전파
- 네트워크 대역폭 소비: 모든 데이터 변경 사항을 복제하므로 네트워크 대역폭 소비가 많음
- DR 사이트 활용: DR 사이트는 단순 복제본 역할만 수행하며, 실시간 쿼리나 백업 등 다른 용도로 활용할 수 없음
- Data Guard (Active Data Guard)
- 복제 방식: 운영 DB의 리두 로그 파일만 DR 사이트로 전송하고, DR 사이트에서 리두 로그를 적용하여 데이터를 동기화
- 데이터 손상 방지: 운영 DB에서 데이터 손상이 발생해도 DR 사이트에서는 검증 과정을 거쳐 전파될 가능성이 훨씬 적음
- 네트워크 대역폭 소비: 리두 로그만 전송하므로 네트워크 대역폭 소비가 훨씬 적음 (스토리지 복제 대비 27배 감소)
- DR 사이트 활용: DR 사이트에서 실시간 쿼리 (Active Data Guard 옵션 필요), RMAN 백업 등 다양한 용도로 활용
- 데이터 블록 손상 자동 복구: 운영 시스템에 데이터 블록 손상 시 자동으로 DR 사이트의 정상 블록 전송 후 자동 복구
| 비교 항목 | 스토리지 복제 | Data Guard (Active Data Guard) |
| 복제 방식 | 모든 데이터 파일 복제 | 리두 로그 파일 전송 및 적용 |
| 데이터 손상 전파 | 전파됨 | 전파 가능성 낮음 |
| 네트워크 대역폭 소비 | 많음 | 적음 |
| DR 사이트 활용 | 제한적 | 다양함 (실시간 쿼리, 백업 등) |
| 데이터 블록 손상 복구 | 수동 복 | 자동 복구 |
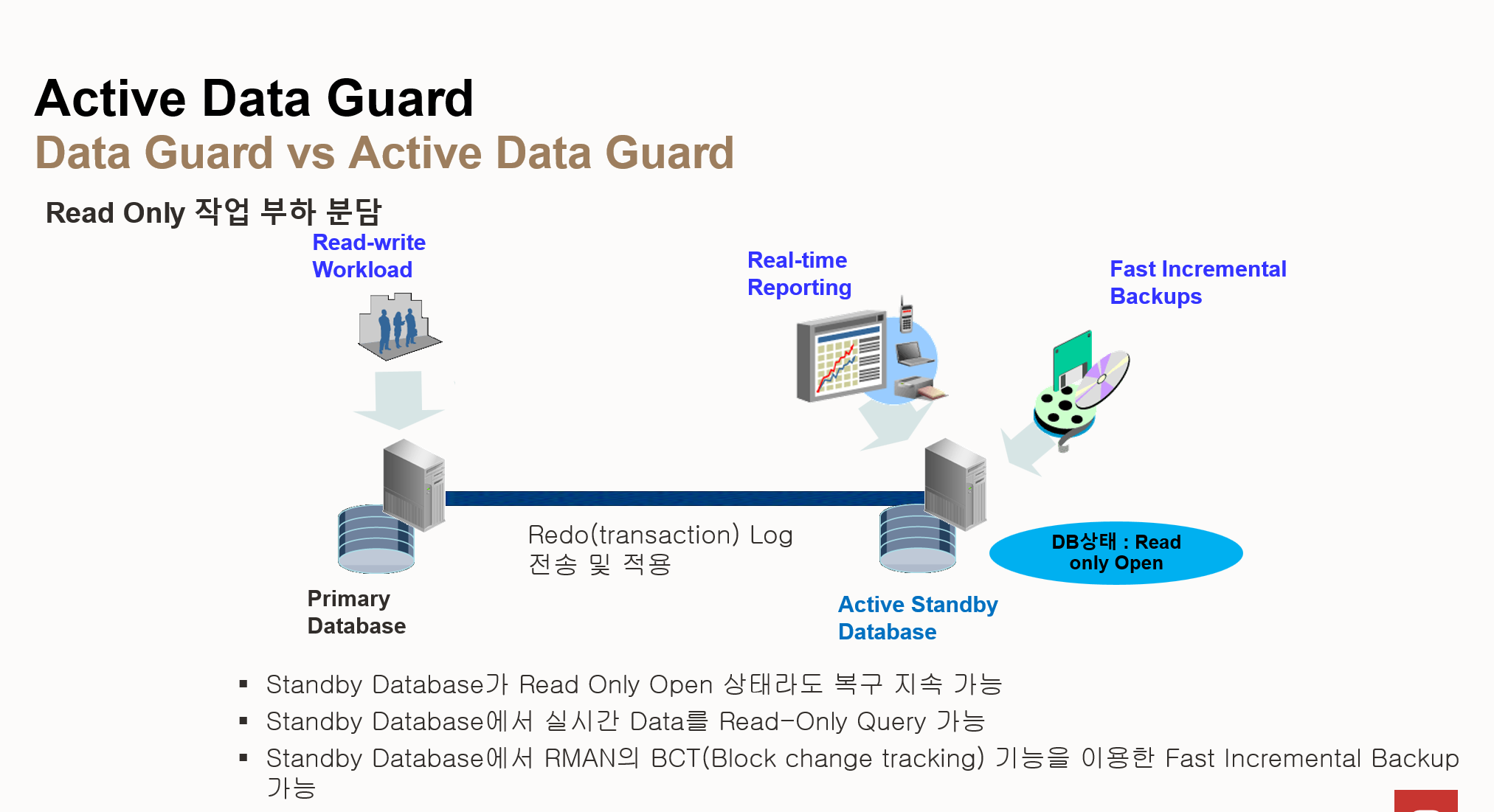
- Active Data Guard 주요 기능
- Read Only 작업 부하 분담: Standby 데이터베이스를 Read Only 모드로 열어 읽기 전용 작업 분산 처리
- Real-time Reporting: Standby 데이터베이스에서 실시간 데이터를 조회하여 보고서 생성
- Fast Incremental Backups: Standby 데이터베이스에서 RMAN의 BCT(Block Change Tracking) 기능을 사용하여 빠른 증분 백업 수행
- 작동 방식
- Redo 로그 전송 및 적용: Primary 데이터베이스의 Redo 로그(트랜잭션 로그)를 Active Standby 데이터베이스로 전송하고 적용하여 데이터 동기화
- Read Only Open 상태 유지: Active Standby 데이터베이스는 Read Only Open 상태를 유지하면서 복구를 지속적으로 수행
- Active Data Guard 장점
- DR 사이트 활용도 향상: Standby 데이터베이스를 단순 복제본이 아닌 다양한 용도로 활용하여 DR 사이트의 활용
- Primary 데이터베이스 부하 감소: 읽기 전용 작업을 Standby 데이터베이스로 분산하여 Primary 데이터베이스의 부하 감소
- 빠른 백업 및 복구: BCT 기능을 사용하여 빠른 증분 백업 및 복구 수행
| 항목 | Active Data Guard | Data Guard |
| 라이선스 | 유료 | 무료 (EE 옵션에 포함) |
| 데이터 복구 중 Standby 조회 | 가능 | 불가능 |
| 자동 블록 복구 | 가능 | 불가능 |
| RMAN BCT (Block Change Tracking) | 지원 | 미지원 |
| Data Guard Rolling Upgrade | 지원 | 미지원 |
| DML redirection | 지원 | 미지원 |
'Oracle Database > Training' 카테고리의 다른 글
| 5장. ACO (Advanced Compression Option) (0) | 2025.03.10 |
|---|---|
| 4장. In-Memory (0) | 2025.03.10 |
| 3장. Backup and Recovery (0) | 2025.03.06 |
| 1장. Administration (0) | 2025.03.05 |